文件 列出文件 ls ls 命令用于显示目录或文件名的内容。ls 将每个由 Directory 参数指定的目录或者每个有 File 参数指定的名称写道标准输出,以及你所要求的和标志一起的其他信息。如果不指定参数,ls 命令显示当前目录的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 用法:ls [选项]... [文件]...
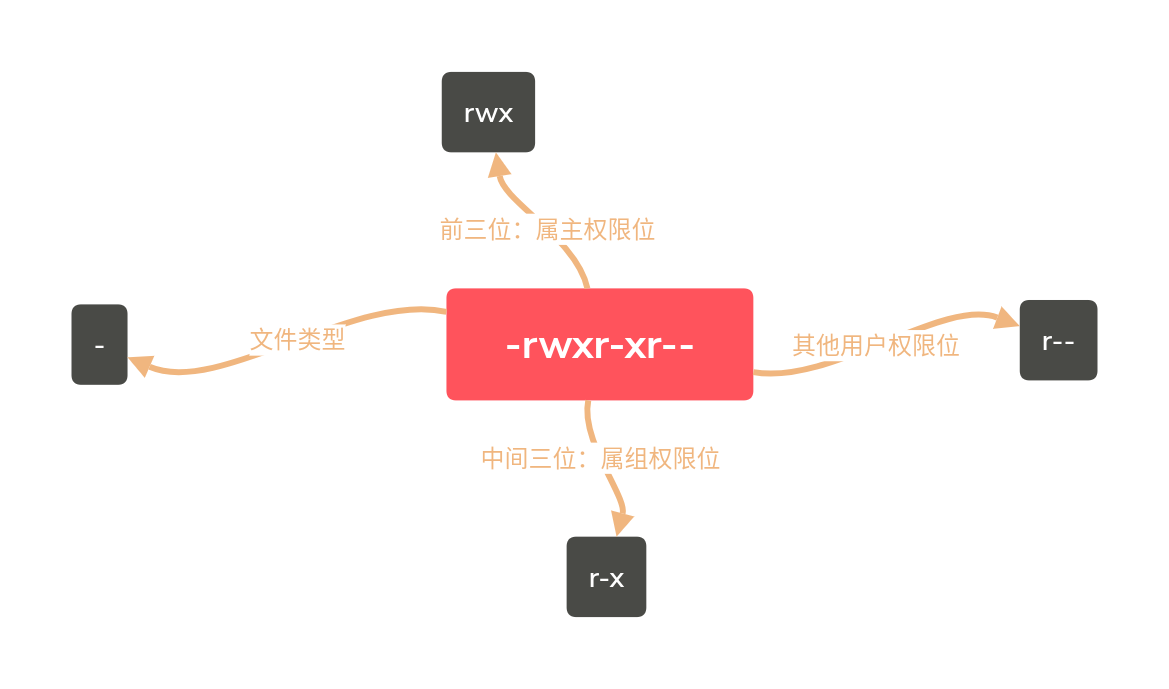
文件的类型 命令 ls -l 输出,第一列信息表示的文件的类型和读写权限,例如:
1 2 3 4 $ pwd
第一列字段由 10 个字符组成,其中第一个字符会有 6 中不同的字符,分别是:
- 普通文件
d 文件夹
b 块设备文件,硬盘(/dev/sda)、光盘(/dev/cdrom)等
c 字符设备文件,内存(/dev/mem)、终端(/dev/tty)、黑洞(/dev/null)等
l 软连接文件
s 套接字文件
文件的权限 在 Linux 中的每个文件或目录都包含有访问权限,这些访问权限决定了谁能访问和如何访问这些文件和目录。
用户分组 对于一个文件来说,可以针对 3 种不同的用户类型设置不同的访问权限。
OWNER 所有者,指创建文件的用户。GROUP 用户组,用户组是指一组相似用户。用户组中的单个用户能够设置其所在用户组访问该用户文件的权限。OTHER 其他用户,用户也可以将自己的文件向系统内的其他所有用户开放。
chown 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 说明:更改与文件关联的所有者或组"root" 。"staff" 。"root" 。
chgrp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 说明:变更文件或目录的所属群组"staff" 。"staff" 。
文件权限 对于每个文件来说,文件所有者或超级用户可以设置文件的可读、可写和可执行权限,他们分别是r 、w 、x 。
r(Read,读取) 对于文件而言,可以读取文件内容;对于目录而言,具有浏览目录的权限。w(Write,写入) 对于文件而言,具有新增、修改文件内容的权限;对于目录而言,具有移动、删除目录的权限。x(eXecute,执行) 对于文件而言,具有执行文件的权限;对于目录而言,该用户具有进入目录的权限
Linux 文件的权限位图:
chmod 1 2 3 4 5 6 7 8 9 10 说明:用来变更文件或目录的权限
文件的修改时间 通过 ls -l 查看 /tmp 下文件的详细信息,其中第 6 列就是文件的修改时间,例如:
1 2 3 4 5 6 7 $ ls -l /tmp
touch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 说明:将每个文件的访问和修改该事件修改为当前时间;当一个文件不存在时,创建这个空文件(除非提供 -c 或 -h 参数)。
寻找文件 在 UNIX/Linux 下寻找文件的机制很强大,使用 find 命令与其他工具结合时,你就能:
find 命令的参数 find 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 说明:在指定目录下查找文件exec <执行指令>:假设find指令的回传值为True,就执行该指令;false :将find指令的回传值皆设为False;print ”参数类似,但会把结果保存成指定的列表文件;printf ”参数类似,但会把结果保存成指定的列表文件;help 或——help :在线帮助;exec ”类似,但在执行指令之前会先询问用户,若回答“y”或“Y”,则放弃执行命令;print :假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为每列一个名称,每个名称前皆有“./”字符串;printf <输出格式>:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式可以自行指定;true :将find指令的回传值皆设为True;type <文件类型>:只寻找符合指定的文件类型的文件;type ”参数类似,差别在于它针对符号连接检查。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 $ find /etc -iname "*rc" -print "*rc" -exec cp {} /tmp/rcfile/ \; $ls /tmp/rcfile"*.txt" type d -print
遍历文件 在使用 find 命令的 -exec 选项处理匹配到的文件时,find 命令将所有匹配到的文件一起传递给 exec 执行。但有些系统对能够传递给 exec 的命令长度有限制,这样在 find 命令运行几分钟之后,就会出现溢出的错误。错误信息通常是“参数列太长”或“参数列溢出”。这就是 xargsfind 命令一起使用。
find 把匹配到的文件传递给 xargs 命令,xargs 命令每次值获取一部分文件而不是全部,不像 -exec 那样。这样他就可以先处理最先获取到的一部分文件,然后是下一批,依次处理。
另外,-exec 再处理每个文件时,都会发起一个进程;而使用 xargs 只会生成一个进程。这样,两个命令对系统资源的占用就显而易见了。
示例
1 2 3 4 5 6 $ find /tmp -maxdepth 1 -type f -print | xargs file
比较文件 使用 comm 比较排序后文件 comm 命令会一行行地比较两个已排序文件的差异,并将结果显示出来。要求被比较的文件需先完成排序。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat test.txt
使用 diff 比较文件 diff 命令会逐行比较两个文本文件,列出其不同之处。他比 comm 命令能完成更加复杂的检查。他对给出的文件进行系统的检查,并且显示两个文件中所有不同的行,不要求实现对文件进行排序。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ cat test.txt
diff 命令的输出格式
Lines Affected in File1
Action
Lines Affected in File2
Number1
a
Num2[,Number3]
Num1[,Number2]
d
Number3
Num1[,Number2]
c
Num3[,Number4]
diff 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 说明:逐行比较文本文件,也可以比较目录内容in two columnswhich C function each change is in 't follow symbolic links -N, --new-file 不存在的文件以空文件方式处理 --unidirectional-new-file 若第一文件不存在,以空文件处理 --ignore-file-name-case 忽略文件名大小写的区别 --no-ignore-file-name-case 不忽略文件名大小写的区别 -x, --exclude=模式 排除匹配 <模式> 的文件 -X, --exclude-from=文件 排除所有匹配在<文件>中列出的模式的文件 -S, --starting-file=文件 当比较目录時,由<文件>开始比较 --from-file=文件1 将<文件1>和操作数中的所有文件/目录作比较; <文件1>可以是目录 --to-file=文件2 将操作数中的所有文件/目录和<文件2>作比较; <文件2>可以是目录 -i, --ignore-case 忽略文件内容大小写的区别 -E, --ignore-tab-expansion 忽略由制表符宽度造成的差异 -Z, --ignore-trailing-space 忽略每行末端的空格 -b, --ignore-space-change 忽略由空格数不同造成的差异 -w, --ignore-all-space 忽略所有空格 -B, --ignore-blank-lines 忽略任何因空行而造成的差异 -I, --ignore-matching-lines=正则 若某行完全匹配 <正则>,则忽略由该行造成的差异 -a, --text 所有文件都以文本方式处理 --strip-trailing-cr 去除输入内容每行末端的回车(CR)字符 -D, --ifdef=名称 输出的内容以 ‘#ifdef <名称>’ 方式标明差异 --GTYPE-group-format=GFMT 以 GFMT 格式处理 GTYPE 输入行组 --line-format=LFMT 以 LFMT 格式处理每一行资料 --LTYPE-line-format=LFMT 以 LFMT 格式处理 LTYPE 输入的行 These format options provide fine-grained control over the output of diff, generalizing -D/--ifdef. LTYPE 可以是 “old”、“new” 或 “unchanged”。GTYPE 可以是 LTYPE 的选择 或是 “changed”。 (仅)GFMT 可包括: %< 该组中每行属于<文件1>的差异 %> 该组中每行属于<文件2>的差异 %= 该组中同时在<文件1>和<文件2>出现的每一行 %[-][宽度][.[精确度]]{doxX}字符 以 printf 格式表示该<字符>代表的内容 大写<字符>表示属于新的文件,小写表示属于旧的文件。<字符>的意义如下: F 行组中第一行的行号 L 行组中最后一行的行号 N 行数 ( =L-F+1 ) E F-1 M L+1 %(A=B?T:E) 如果 A 等于 B 那么 T 否则 E (仅)LFMT 可包括: %L 该行的内容 %l 该行的内容,但不包括结束的换行符 %[-][宽度][.[精确度]]{doxX}n 以 printf 格式表示的输入行号 GFMT 或 LFMT 都可包括: %% % %c' C' 单个字符 C %c' \OOO' 八进制码 OOO 所代表的字符 C 字符 C(处上述转义外的其他字符代表它们自身) -d, --minimal 尽可能找出最小的差异。 --horizon-lines=数量 保持<数量>行的一致前后缀 --speed-large-files 假设文件十分大而且文件中含有许多微小的差异 --color[=WHEN] colorize the output; WHEN can be ' never', ' always', or ' auto' (the default) --palette=PALETTE the colors to use when --color is active; PALETTE is a colon-separated list of terminfo capabilities
comm 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 说明:逐行比较已排序的文件文件1 和文件2。When FILE1 or FILE2 (not both) is -, read standard input.
其他文本比较方法 vimdiff